Memory augmentation for document heavy enterprise use case
Document heavy enterprise use case
Enterprise LLM use cases typically rely on a knowledge base comprising a large collection of documents, such as company-specific policies, facts, or processes. When building LLM systems (e.g., customer support chatbots or workflow automation agents), organizations aim to inject the knowledge from these documents into their LLMs to:
Mitigate legal/operational risks by minimizing hallucinations that could lead to incorrect warranties, pricing errors, or non-compliant advice.
Enforce brand consistency and compliance by grounding responses in proprietary documentation (e.g., product specs, policy manuals, CRM data).
The process of augmenting LLMs with external knowledge (structured or unstructured) to improve factual accuracy, task-specific performance, controllability, and thereby reducing hallucinations is referred to as Knowledge Injection (KI). KI is critical for ensuring the effectiveness and safety of enterprise LLM applications. For instance, Yext’s KI method improved response quality by 33% in enterprise tasks by injecting knowledge graph data [ref 2].
On the other hand, neglecting it can result in significant losses for companies, as demonstrated by incidents involving Air Canada [ref 1].
Knowledge Injection solutions
Existing knowledge injection (KI) methods, based on how knowledge is represented in the LLM system, can be broadly categorized into two main types:
Parametric methods
Non-parametric methods
Parametric knowledge injection involves representing knowledge as neural network (NN) weights. This can take the form of modifying an LLM’s original weights via approaches such as continual pre-training, supervised fine-tuning, or meta-learning-based weight editors [ref 3, 4]. Alternatively, knowledge can be encoded into additional weights outside the original LLM weights, such as side matrices [ref 5, 6], side neurons [ref 7, 8], or even an auxiliary model [ref 9]. These methods transfer knowledge from external knowledge bases (e.g., company documents) into NN weights through optimization of those additional weights.
Non-parametric knowledge injection, on the other hand, represents knowledge in formats that are not NN weights. It may retain knowledge in its text form (as in prompt engineering and all RAG methods) or utilize Key-Value (KV) vector representations [ref 10, 11, 12].
With this broad categorization in mind, let’s take a closer look at the challenges and trade-offs involved in these methods.
Parametric knowledge injection methods that modify original weights or use limited additional weights face a challenge: selecting which subset of weights to update when encoding a large set of knowledge, as seen in enterprise LLM use cases.
If the full set of model weights is updated, the edits become non-local, potentially leading to overfitting, where the model becomes overly specialized on the injected knowledge. On the other hand, updating a small subset of weights creates local edits with high knowledge density. However, this approach can introduce conflicts among the encoded knowledge, potentially causing catastrophic forgetting or memory clashes, where previously stored information is overwritten or lost [ref 5]. If enterprises aim to mitigate these issues, they can employ delicate training procedures and rigorous evaluations to carefully balance knowledge updates. However, this requires additional development effort, increasing the overall engineering complexity. Moreover, for larger models, the computational cost of retraining or fine-tuning even a subset of weights can be substantial, further adding to the financial burden.
A sparse injection strategy, where specific subsets of weights are dedicated to different knowledge segments (e.g., knowledge 1-5 is assigned to one weight subset, knowledge 6-10 to another), as explored in [ref 5], offers some relief. However, this method is limited by the finite number of available weight subsets, eventually encountering the same issue of memory clashes when the knowledge capacity is exceeded.
What if we could use an extremely large or even unlimited number of additional weights, as proposed in [ref 6]? While this approach enables encoding vast amounts of knowledge, it requires an indexing or routing step to map additional weights to specific injected knowledge. During inference, only a subset of the additional weights is triggered, making it essential to determine which subsets are relevant for the current generation. Examples of such indexing or routing steps include Neuron Indexing with a vector database in MELO [ref 6], a classifier-based routing mechanism in SERAC [ref 9], and a rule-based router in WISE [ref 5]. This indexing or routing is akin to the similarity based retrieval step in retrieval-augmented generation (RAG).
It seems there is no robust and straightforward solution to the dilemmas inherent in parametric knowledge injection. This brings us to non-parametric KI methods.
The primary motivation behind KV-based non-parametric KI methods is to reduce computational overhead during inference by leveraging pre-computed Key-Value (KV) vectors. Instead of relying on real-time computation, this approach uses pre-stored KV vectors that correspond to external knowledge or document chunks. During inference, for a given query, the relevant KV vectors are retrieved through a similarity-based retrieval process, akin to the steps in RAG.
However, storing KV vectors is significantly more memory-intensive than storing raw text. This can become prohibitively expensive as the knowledge base scales, which is often the case in enterprise settings.
Considering all the afore-mentioned points:
The locality dilemma in parametric KI methods with original weights or limited additional weights.
The retrieval dependency for parametric KI methods with infinite additional weights
The high memory cost of storing KV vectors for large knowledge bases in enterprise use cases.
The most practical choice for enterprise knowledge injection remains non-parametric methods that retain knowledge in its original text form. While both prompt engineering and Retrieval-Augmented Generation (RAG) fall into this category, RAG stands out as the more scalable solution—an essential factor for enterprise use cases.
Optimize RAG for document heavy enterprise use cases
With RAG identified as the most suitable approach for enterprise knowledge injection, the focus shifts to enhancing its performance for document-heavy use cases. We begin by exploring the best combination of different modular components in RAG.
The main components in RAG include:
Document Parser: Services or tools like Unstructured [ref 16], Omini AI [ref 17], and Azure Document Intelligence [ref 18] can extract text from diverse document formats (PDFs, images, scanned files). These document parsers are the entry point for using enterprise unstructured data in the RAG system.
Chunker: Chunkers segment extracted document contents into manageable pieces, optimizing them for retrieval and embedding. Some examples include:
Unstructured Chunk by Title: Segments based on document titles or section headers.
Semantic Chunker [ref 19, 20]: Breaks content into logical units based on embedding vectors and similarity scores, ensuring coherent chunks for downstream tasks.
Embedder: Embedders convert text into high-dimensional vectors that encode semantic meaning.
Nomic [ref 21]
OpenAI embedding models [ref 22]
Jina & Late Embedding [ref 23]
Vector Database (VectorDB): Tools like Qdrant, Pinecode, Milvus, Chroma and Weaviate can create efficient embedding-based indexes, enabling fast and accurate similarity searches that facilitate the quick retrieval of relevant chunks. A robust Vector Database (VectorDB) is essential for RAG systems to scale effectively while maintaining responsiveness, especially in large-scale, document-heavy environments.
Some additional components that can lead to better RAG performance include:
Query Expander
Enhances user queries by rephrasing or appending related terms, ensuring broader and more accurate search results.Reranker
Reranks retrieved results based on relevance or task-specific criteria from multiple sources (e.g. multiplier embedders), improving the quality of the final retrieval output.Passage Processor
Applies additional transformations or enrichments to retrieved passages, such as summarization or language correction, before they are used in generation.Extractor
Additional processing applied to retrieved text chunks. For example, an LLM-based extractor can refine raw text by targeting specific information, such as identifying compliance-related policies, extracting verifiable statements or key facts, or converting tabular data into structured formats for downstream analysis.
Build pipelines with components
We build pipelines that integrate RAG components to enable easy optimization and support various RAG logic. For example, two basic pipelines—a linear ingestion pipeline and a linear query pipeline—are illustrated in Figure 1 below.
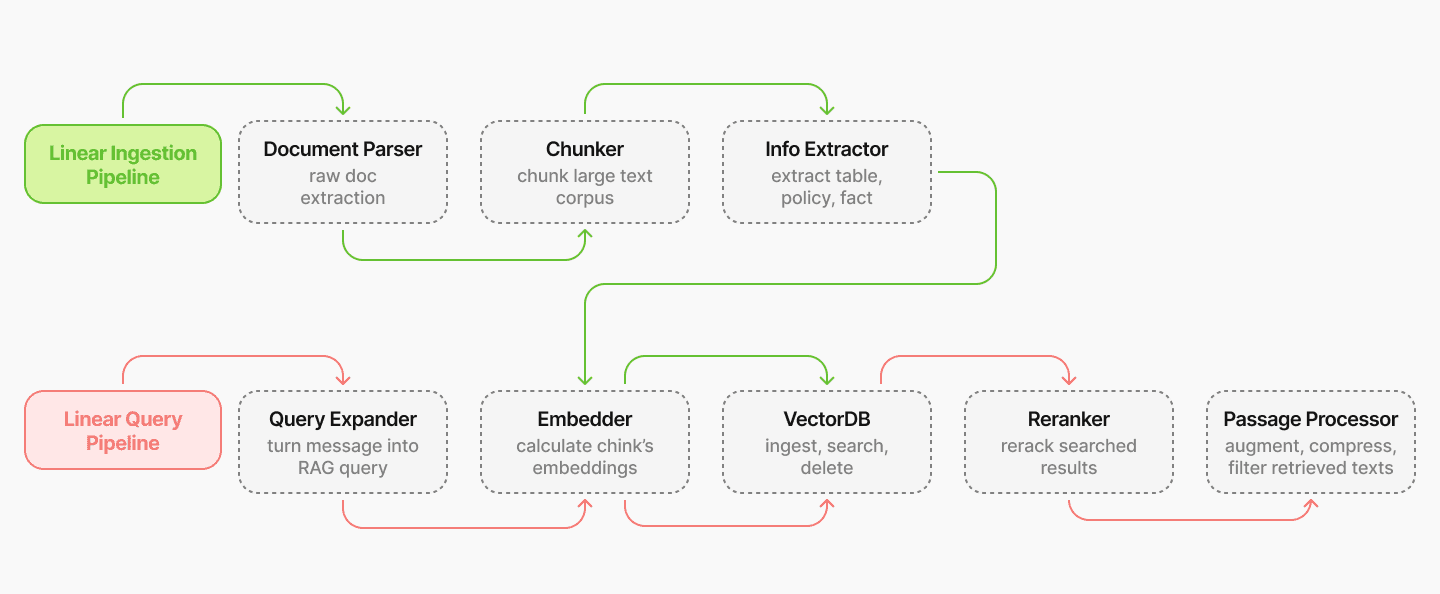
Figure 1
In these linear pipelines, RAG components are connected in a sequential manner, where the output of one component becomes the input to the next. For instance, in the linear ingestion pipeline, the document parser extracts content from raw documents, which is then processed by the chunker to create smaller content pieces. These chunks are subsequently processed by the extractor and then embedded by the embedder, and the resulting embedding vectors are ingested into the vector database, preparing them for retrieval in the query pipeline.
Each RAG component is designed to be modular and configurable, allowing us to experiment with different component combinations with ease, evaluate their performance, and select the optimal component combination for each specific use case.
Importantly, pipelines are not restricted to linear structures; they can also incorporate complex logic, such as loops. For instance, an iterative ingestion pipeline could include a loop between these four components: Extractor, Query Expander, Embedder, and VectorDB. In this configuration, the extractor retrieves content iteratively from the VectorDB, refining its extraction with each query iteration based on the most recent information at hand. This iterative process enables the pipeline to construct more complete information by retrieving raw document data in multiple stages, similar to the methods proposed in [ref 13, 14].
To ensure robustness and efficiency in our RAG pipelines, we implemented our pipelines using Temporal, drawing inspiration from [ref 15]. Temporal offers several advantages, particularly in enhancing the durability and resilience of workflows. By automatically retrying failed tasks within each RAG component and maintaining the state of the RAG pipeline, Temporal ensures that no tasks are lost due to errors or interruptions. This durability allows our pipelines to recover seamlessly from failures without data loss or manual intervention. Moreover, Temporal enables targeted retries of failed steps, eliminating the need to rerun the entire pipeline, thus saving time and resources.
Experimental results
In this section, we present partially our optimization efforts on the linear ingestion and query pipelines by comparing various combinations of RAG components (document parser, chunker, and embedder). Additionally, we highlight the effectiveness of incorporating an extractor into the RAG pipeline for processing documents with complex content. The performance of these RAG configurations is evaluated on our verification use case [link to blog], using the F1 score of the verifier as the primary metric.
Comparing different RAG component combinations
We evaluate the performance of different models—GPT-4o (2024-11-20), the base LLaMA-8B model, and a fine-tuned LLaMA-8B model—on our verification tasks across various RAG components. Specifically, we systematically vary the document parser, chunker, and embedder, measuring the performance of each combination under the three models. To compare RAG components in isolation such as document parser, we average F1 scores across all other RAG components for each choice of document parser for each model (Figure 2, 3, 4).
Regarding the document parser selection for our specific verification use cases, Omini AI's document parsing outperforms Unstructured but comes at a significantly higher cost due to its use of vision-based LLM models for data extraction.
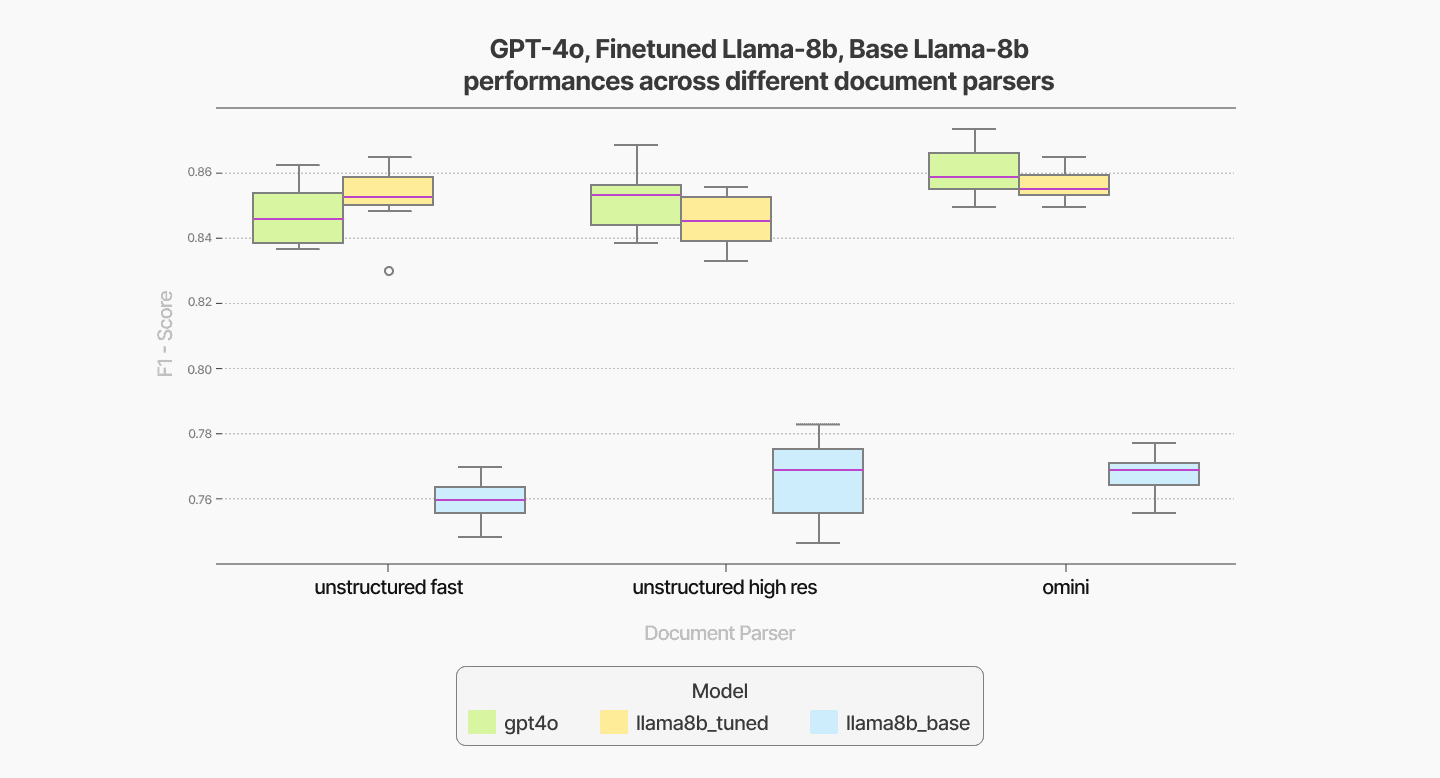
Figure 2
In terms of chunker selection, the Unstructured-by-Title chunking method delivers results comparable to the more expensive semantic chunking approach, making it a cost-effective alternative.
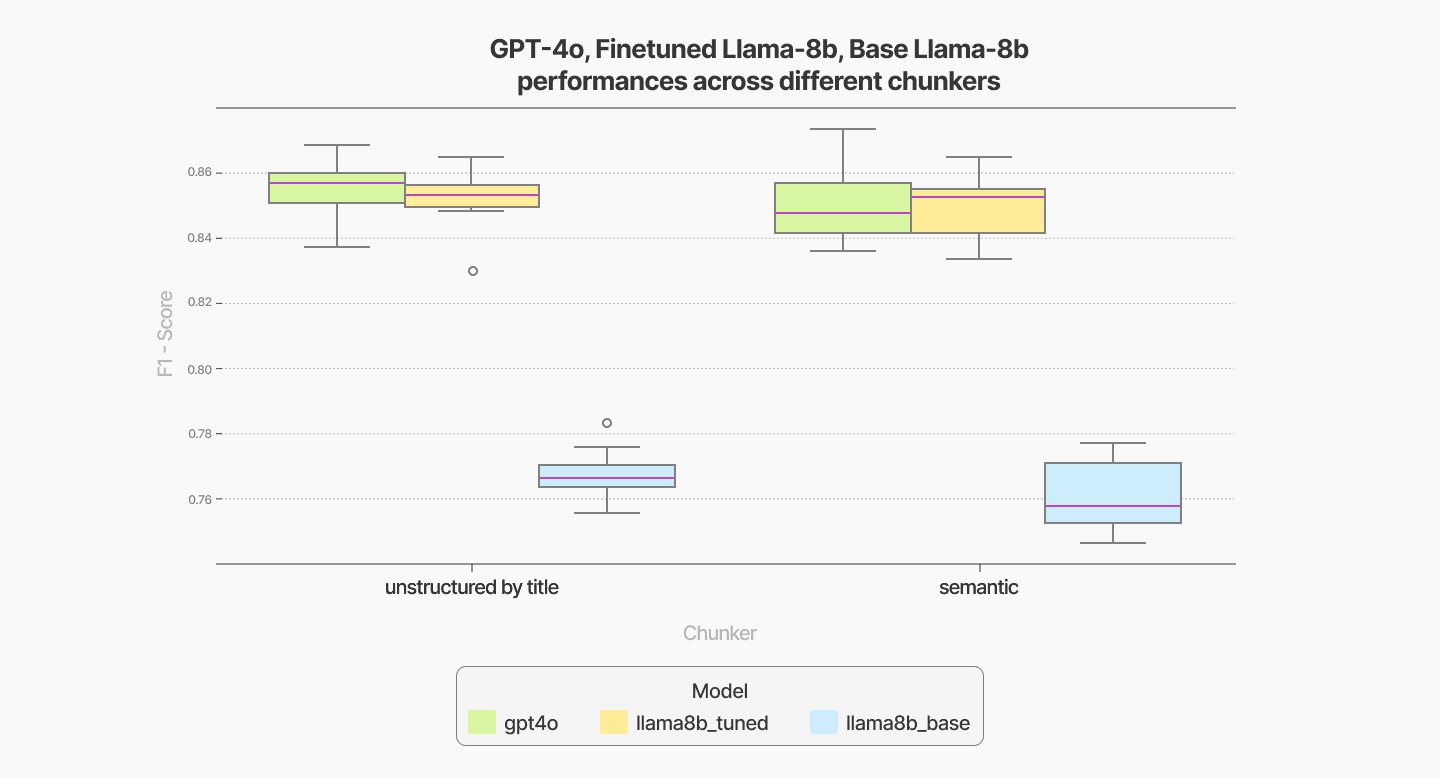
Figure 3
For embedders, the Nomic embedder demonstrates slightly better performance compared to other options like Jina and OpenAI, offering a balance of quality and efficiency.
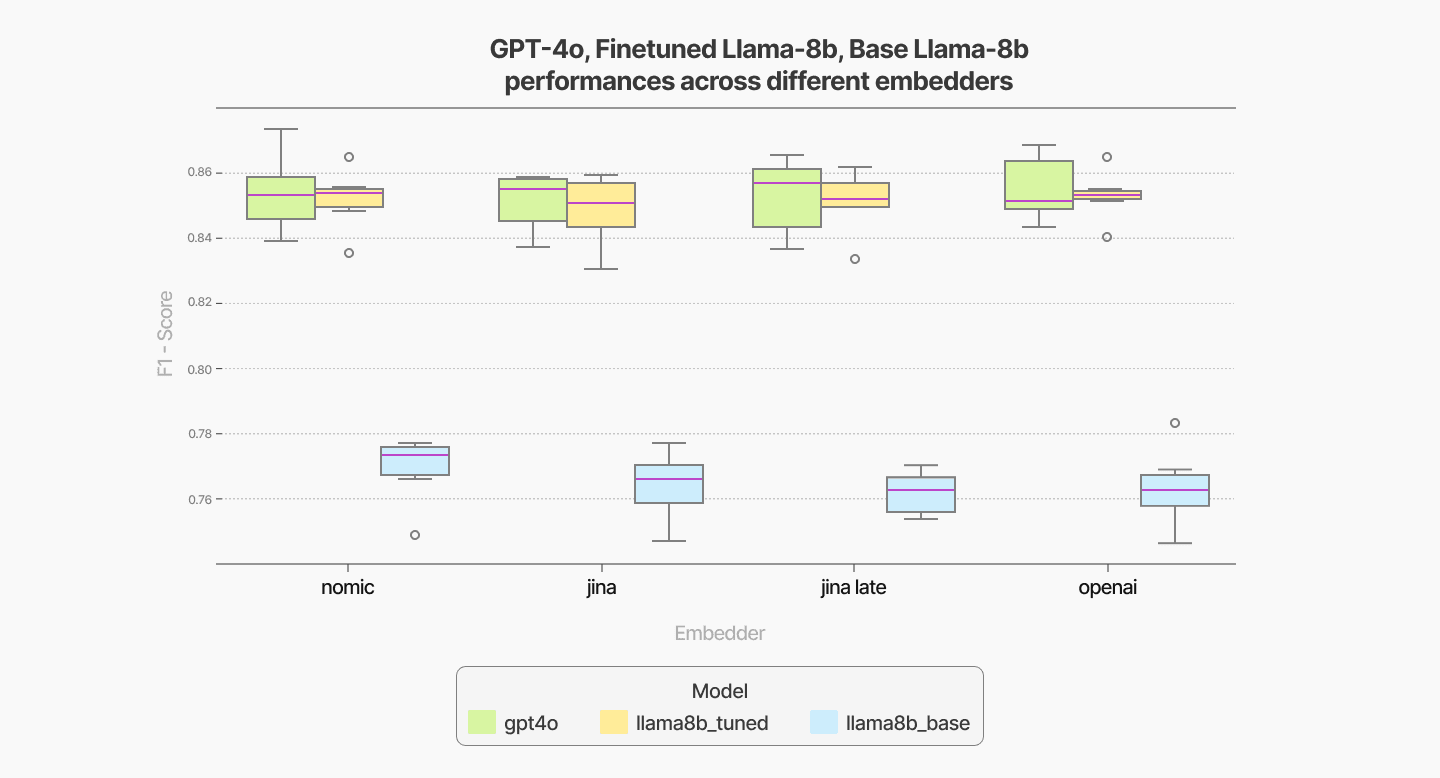
Figure 4
As a separate note, we can see the effectiveness of the finetuning as we are able to drastically improve the performance of the 8B model and make it competitive to the GPT-4o model.
Effectiveness of Extractor in the pipeline
We briefly studied the impact of including a chunk-content-specific extractor on the final performance of Q&A tasks involving PDFs with complex structures, such as tables and charts. Using different document parsers with the same downstream chunker, embedder, and VectorDB in our pipeline, we compared their performances without an extractor. The results, shown in Figure 5, indicate that the highest F1 score without an extractor was achieved using Azure Document Intelligence, reaching approximately 0.89.
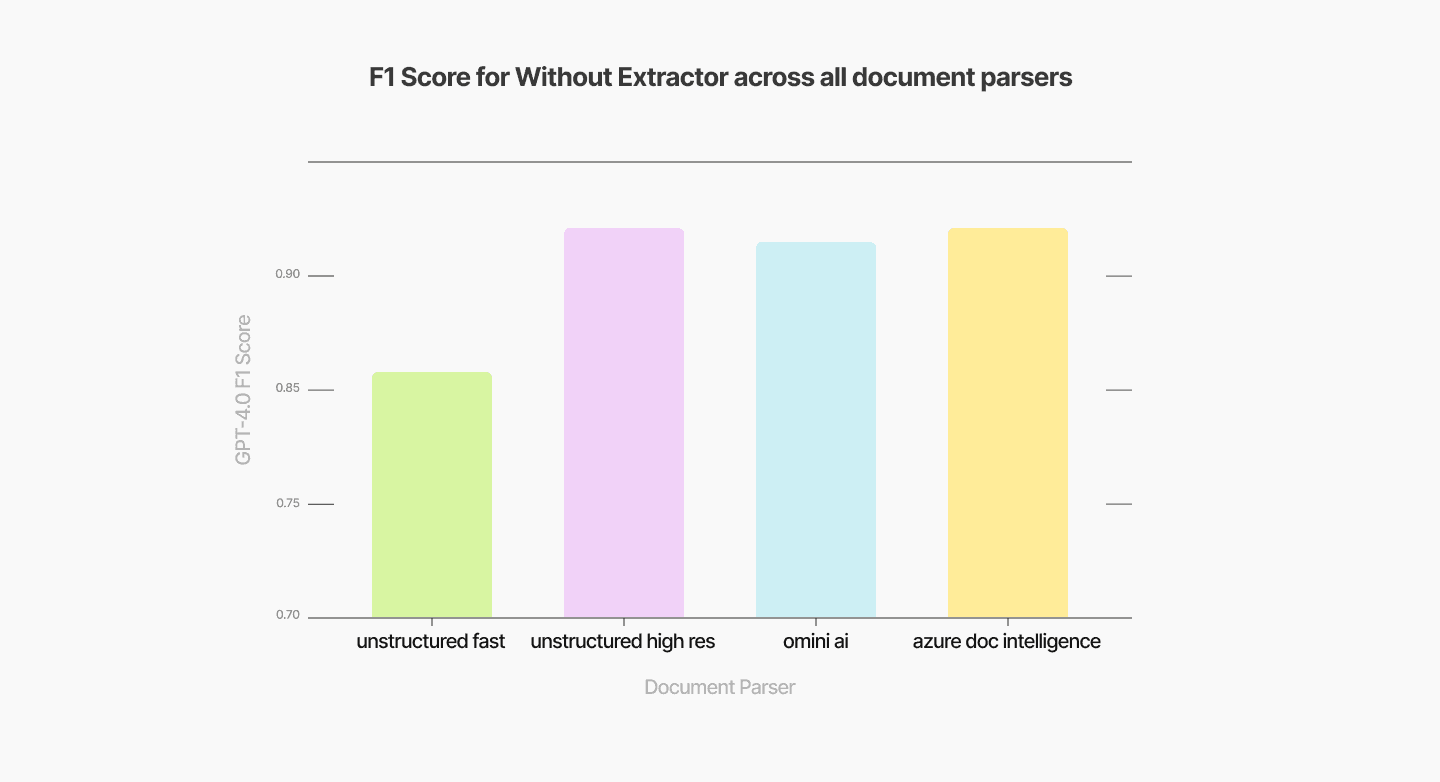
Figure 5
When a chunk-type-specific extractor was added to the pipeline, the performance improved significantly, boosting the F1 score to 0.92, as shown in Figure 6. It is worth noting that we evaluated extractor performance only for Unstructured High Res and Azure Document Intelligence parsers, as they provide a straightforward method for chunk-type classification.
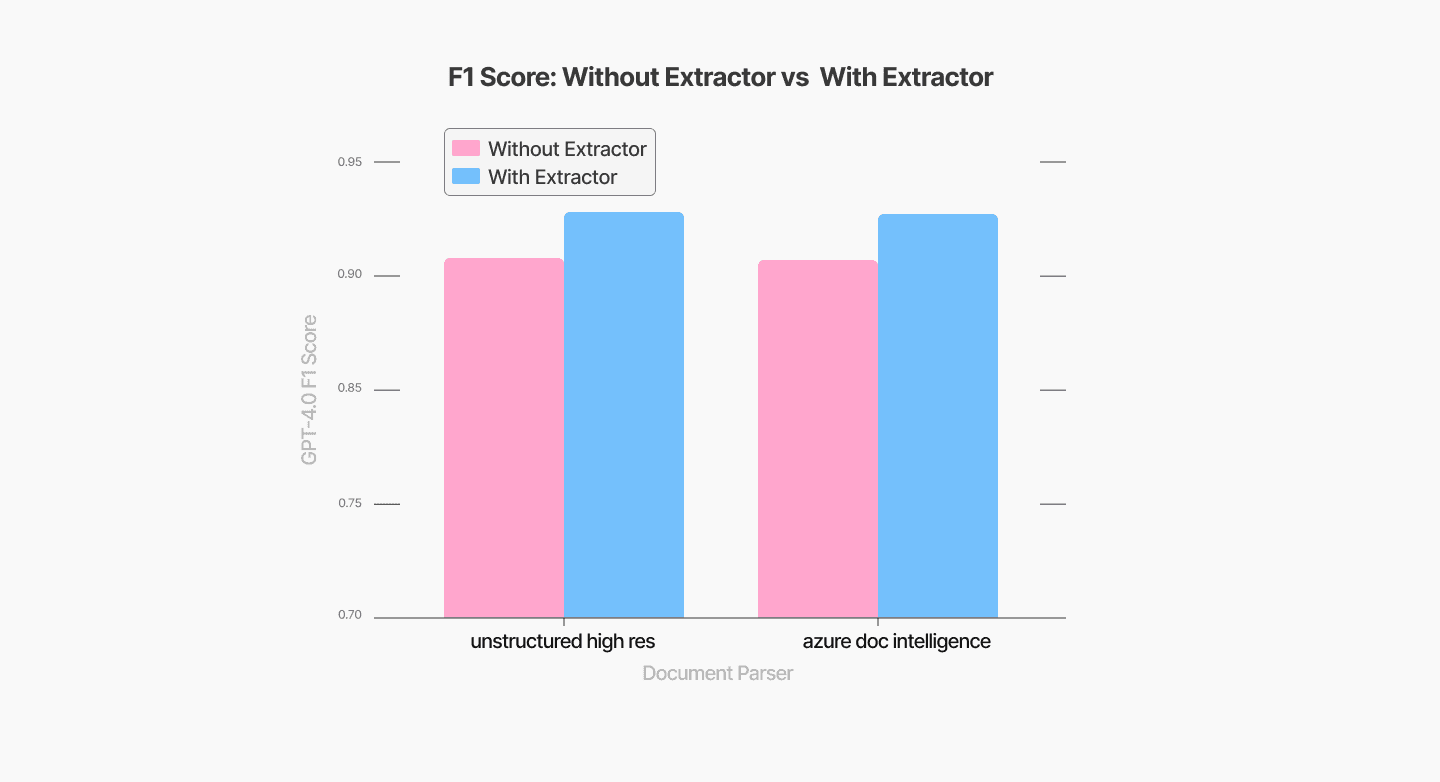
Figure 6
This analysis demonstrates the benefits of incorporating an extractor into the RAG pipeline. Expanding on this idea, we can also implement policy or instruction extraction for chunks that are policy-heavy in our enterprise use cases. However, it is important to note that such enhancements increase the complexity and cost of the RAG ingestion pipeline.
Conclusions
Retrieval-Augmented Generation (RAG) stands out as the most suitable knowledge injection approach for enterprise knowledge-intensive use cases, offering flexibility and scalability. To maximize the effectiveness of RAG, use-case-dependent optimization is critical. From selecting the right combination of document parsers, chunkers, and embedders to incorporating advanced techniques like chunk-type-specific extractors, each component can be tailored to the unique requirements of the use case. This level of optimization can significantly enhance performance, as demonstrated by improvements in F1 scores in our experiments.
Equally important is designing a modular RAG pipeline, which allows for flexible experimentation with different components. Additionally, integrating tools like Temporal strengthens the reliability and scalability of LLM-driven, knowledge-intensive processes and services.
References
[1] What Air Canada Lost In ‘Remarkable’ Lying AI Chatbot Case https://www.forbes.com/sites/marisagarcia/2024/02/19/what-air-canada-lost-in-remarkable-lying-ai-chatbot-case/
[2] Yext Showcases Knowledge Injection Research With Large Language Models | Yext
[3] Fast Model Editing at Scale [2110.11309] Fast Model Editing at Scale
[4] Massive Editing for Large Language Models via Meta Learning https://openreview.net/forum?id=L6L1CJQ2PE
[5] WISE: Rethinking the Knowledge Memory for Lifelong Model Editing of Large Language Models [2405.14768] WISE: Rethinking the Knowledge Memory for Lifelong Model Editing of Large Language Models
[6] MELO: Enhancing Model Editing with Neuron-Indexed Dynamic LoRA https://arxiv.org/abs/2312.11795
[7] Transformer-Patcher: One Mistake Worth One Neuron Transformer-Patcher: One Mistake Worth One Neuron | OpenReview
[8] Calibrating Factual Knowledge in Pretrained Language Models [2210.03329] Calibrating Factual Knowledge in Pretrained Language Models
[9] Memory-Based Model Editing at Scale [2206.06520] Memory-Based Model Editing at Scale
[10] Augmenting Language Models with Long-Term Memory [2306.07174] Augmenting Language Models with Long-Term Memory
[11] Memory^3 2407.01178
[12] InfLLM: Training-Free Long-Context Extrapolation for LLMs with an Efficient Context Memory 2402.04617
[13] Retrieve, Summarize, Plan: Advancing Multi-hop Question Answering with an Iterative Approach 2407.13101
[14] PlanRAG: A Plan-then-Retrieval Augmented Generation for Generative Large Language Models as Decision Makers 2406.12430
[15] BlogPost: durable-rag-with-temporal-and-chainlit https://temporal.io/blog/durable-rag-with-temporal-and-chainlit
[16] Unstructured webpage https://unstructured.io/
[17] OmniAI webpage https://getomni.ai/
[18] Azure Document Intelligence https://documentintelligence.ai.azure.com
[19] Semantic chunkers https://github.com/aurelio-labs/semantic-chunkers
[20] Chonkie webpage https://docs.chonkie.ai/getting-started/installation
[21] Nomic AI webpage https://www.nomic.ai/
[22] OpenAI embedding models https://openai.com/index/new-embedding-models-and-api-updates/
[23] Jina AI webpage https://jina.ai/
Document heavy enterprise use case
Enterprise LLM use cases typically rely on a knowledge base comprising a large collection of documents, such as company-specific policies, facts, or processes. When building LLM systems (e.g., customer support chatbots or workflow automation agents), organizations aim to inject the knowledge from these documents into their LLMs to:
Mitigate legal/operational risks by minimizing hallucinations that could lead to incorrect warranties, pricing errors, or non-compliant advice.
Enforce brand consistency and compliance by grounding responses in proprietary documentation (e.g., product specs, policy manuals, CRM data).
The process of augmenting LLMs with external knowledge (structured or unstructured) to improve factual accuracy, task-specific performance, controllability, and thereby reducing hallucinations is referred to as Knowledge Injection (KI). KI is critical for ensuring the effectiveness and safety of enterprise LLM applications. For instance, Yext’s KI method improved response quality by 33% in enterprise tasks by injecting knowledge graph data [ref 2].
On the other hand, neglecting it can result in significant losses for companies, as demonstrated by incidents involving Air Canada [ref 1].
Knowledge Injection solutions
Existing knowledge injection (KI) methods, based on how knowledge is represented in the LLM system, can be broadly categorized into two main types:
Parametric methods
Non-parametric methods
Parametric knowledge injection involves representing knowledge as neural network (NN) weights. This can take the form of modifying an LLM’s original weights via approaches such as continual pre-training, supervised fine-tuning, or meta-learning-based weight editors [ref 3, 4]. Alternatively, knowledge can be encoded into additional weights outside the original LLM weights, such as side matrices [ref 5, 6], side neurons [ref 7, 8], or even an auxiliary model [ref 9]. These methods transfer knowledge from external knowledge bases (e.g., company documents) into NN weights through optimization of those additional weights.
Non-parametric knowledge injection, on the other hand, represents knowledge in formats that are not NN weights. It may retain knowledge in its text form (as in prompt engineering and all RAG methods) or utilize Key-Value (KV) vector representations [ref 10, 11, 12].
With this broad categorization in mind, let’s take a closer look at the challenges and trade-offs involved in these methods.
Parametric knowledge injection methods that modify original weights or use limited additional weights face a challenge: selecting which subset of weights to update when encoding a large set of knowledge, as seen in enterprise LLM use cases.
If the full set of model weights is updated, the edits become non-local, potentially leading to overfitting, where the model becomes overly specialized on the injected knowledge. On the other hand, updating a small subset of weights creates local edits with high knowledge density. However, this approach can introduce conflicts among the encoded knowledge, potentially causing catastrophic forgetting or memory clashes, where previously stored information is overwritten or lost [ref 5]. If enterprises aim to mitigate these issues, they can employ delicate training procedures and rigorous evaluations to carefully balance knowledge updates. However, this requires additional development effort, increasing the overall engineering complexity. Moreover, for larger models, the computational cost of retraining or fine-tuning even a subset of weights can be substantial, further adding to the financial burden.
A sparse injection strategy, where specific subsets of weights are dedicated to different knowledge segments (e.g., knowledge 1-5 is assigned to one weight subset, knowledge 6-10 to another), as explored in [ref 5], offers some relief. However, this method is limited by the finite number of available weight subsets, eventually encountering the same issue of memory clashes when the knowledge capacity is exceeded.
What if we could use an extremely large or even unlimited number of additional weights, as proposed in [ref 6]? While this approach enables encoding vast amounts of knowledge, it requires an indexing or routing step to map additional weights to specific injected knowledge. During inference, only a subset of the additional weights is triggered, making it essential to determine which subsets are relevant for the current generation. Examples of such indexing or routing steps include Neuron Indexing with a vector database in MELO [ref 6], a classifier-based routing mechanism in SERAC [ref 9], and a rule-based router in WISE [ref 5]. This indexing or routing is akin to the similarity based retrieval step in retrieval-augmented generation (RAG).
It seems there is no robust and straightforward solution to the dilemmas inherent in parametric knowledge injection. This brings us to non-parametric KI methods.
The primary motivation behind KV-based non-parametric KI methods is to reduce computational overhead during inference by leveraging pre-computed Key-Value (KV) vectors. Instead of relying on real-time computation, this approach uses pre-stored KV vectors that correspond to external knowledge or document chunks. During inference, for a given query, the relevant KV vectors are retrieved through a similarity-based retrieval process, akin to the steps in RAG.
However, storing KV vectors is significantly more memory-intensive than storing raw text. This can become prohibitively expensive as the knowledge base scales, which is often the case in enterprise settings.
Considering all the afore-mentioned points:
The locality dilemma in parametric KI methods with original weights or limited additional weights.
The retrieval dependency for parametric KI methods with infinite additional weights
The high memory cost of storing KV vectors for large knowledge bases in enterprise use cases.
The most practical choice for enterprise knowledge injection remains non-parametric methods that retain knowledge in its original text form. While both prompt engineering and Retrieval-Augmented Generation (RAG) fall into this category, RAG stands out as the more scalable solution—an essential factor for enterprise use cases.
Optimize RAG for document heavy enterprise use cases
With RAG identified as the most suitable approach for enterprise knowledge injection, the focus shifts to enhancing its performance for document-heavy use cases. We begin by exploring the best combination of different modular components in RAG.
The main components in RAG include:
Document Parser: Services or tools like Unstructured [ref 16], Omini AI [ref 17], and Azure Document Intelligence [ref 18] can extract text from diverse document formats (PDFs, images, scanned files). These document parsers are the entry point for using enterprise unstructured data in the RAG system.
Chunker: Chunkers segment extracted document contents into manageable pieces, optimizing them for retrieval and embedding. Some examples include:
Unstructured Chunk by Title: Segments based on document titles or section headers.
Semantic Chunker [ref 19, 20]: Breaks content into logical units based on embedding vectors and similarity scores, ensuring coherent chunks for downstream tasks.
Embedder: Embedders convert text into high-dimensional vectors that encode semantic meaning.
Nomic [ref 21]
OpenAI embedding models [ref 22]
Jina & Late Embedding [ref 23]
Vector Database (VectorDB): Tools like Qdrant, Pinecode, Milvus, Chroma and Weaviate can create efficient embedding-based indexes, enabling fast and accurate similarity searches that facilitate the quick retrieval of relevant chunks. A robust Vector Database (VectorDB) is essential for RAG systems to scale effectively while maintaining responsiveness, especially in large-scale, document-heavy environments.
Some additional components that can lead to better RAG performance include:
Query Expander
Enhances user queries by rephrasing or appending related terms, ensuring broader and more accurate search results.Reranker
Reranks retrieved results based on relevance or task-specific criteria from multiple sources (e.g. multiplier embedders), improving the quality of the final retrieval output.Passage Processor
Applies additional transformations or enrichments to retrieved passages, such as summarization or language correction, before they are used in generation.Extractor
Additional processing applied to retrieved text chunks. For example, an LLM-based extractor can refine raw text by targeting specific information, such as identifying compliance-related policies, extracting verifiable statements or key facts, or converting tabular data into structured formats for downstream analysis.
Build pipelines with components
We build pipelines that integrate RAG components to enable easy optimization and support various RAG logic. For example, two basic pipelines—a linear ingestion pipeline and a linear query pipeline—are illustrated in Figure 1 below.
Figure 1
In these linear pipelines, RAG components are connected in a sequential manner, where the output of one component becomes the input to the next. For instance, in the linear ingestion pipeline, the document parser extracts content from raw documents, which is then processed by the chunker to create smaller content pieces. These chunks are subsequently processed by the extractor and then embedded by the embedder, and the resulting embedding vectors are ingested into the vector database, preparing them for retrieval in the query pipeline.
Each RAG component is designed to be modular and configurable, allowing us to experiment with different component combinations with ease, evaluate their performance, and select the optimal component combination for each specific use case.
Importantly, pipelines are not restricted to linear structures; they can also incorporate complex logic, such as loops. For instance, an iterative ingestion pipeline could include a loop between these four components: Extractor, Query Expander, Embedder, and VectorDB. In this configuration, the extractor retrieves content iteratively from the VectorDB, refining its extraction with each query iteration based on the most recent information at hand. This iterative process enables the pipeline to construct more complete information by retrieving raw document data in multiple stages, similar to the methods proposed in [ref 13, 14].
To ensure robustness and efficiency in our RAG pipelines, we implemented our pipelines using Temporal, drawing inspiration from [ref 15]. Temporal offers several advantages, particularly in enhancing the durability and resilience of workflows. By automatically retrying failed tasks within each RAG component and maintaining the state of the RAG pipeline, Temporal ensures that no tasks are lost due to errors or interruptions. This durability allows our pipelines to recover seamlessly from failures without data loss or manual intervention. Moreover, Temporal enables targeted retries of failed steps, eliminating the need to rerun the entire pipeline, thus saving time and resources.
Experimental results
In this section, we present partially our optimization efforts on the linear ingestion and query pipelines by comparing various combinations of RAG components (document parser, chunker, and embedder). Additionally, we highlight the effectiveness of incorporating an extractor into the RAG pipeline for processing documents with complex content. The performance of these RAG configurations is evaluated on our verification use case [link to blog], using the F1 score of the verifier as the primary metric.
Comparing different RAG component combinations
We evaluate the performance of different models—GPT-4o (2024-11-20), the base LLaMA-8B model, and a fine-tuned LLaMA-8B model—on our verification tasks across various RAG components. Specifically, we systematically vary the document parser, chunker, and embedder, measuring the performance of each combination under the three models. To compare RAG components in isolation such as document parser, we average F1 scores across all other RAG components for each choice of document parser for each model (Figure 2, 3, 4).
Regarding the document parser selection for our specific verification use cases, Omini AI's document parsing outperforms Unstructured but comes at a significantly higher cost due to its use of vision-based LLM models for data extraction.
Figure 2
In terms of chunker selection, the Unstructured-by-Title chunking method delivers results comparable to the more expensive semantic chunking approach, making it a cost-effective alternative.
Figure 3
For embedders, the Nomic embedder demonstrates slightly better performance compared to other options like Jina and OpenAI, offering a balance of quality and efficiency.
Figure 4
As a separate note, we can see the effectiveness of the finetuning as we are able to drastically improve the performance of the 8B model and make it competitive to the GPT-4o model.
Effectiveness of Extractor in the pipeline
We briefly studied the impact of including a chunk-content-specific extractor on the final performance of Q&A tasks involving PDFs with complex structures, such as tables and charts. Using different document parsers with the same downstream chunker, embedder, and VectorDB in our pipeline, we compared their performances without an extractor. The results, shown in Figure 5, indicate that the highest F1 score without an extractor was achieved using Azure Document Intelligence, reaching approximately 0.89.
Figure 5
When a chunk-type-specific extractor was added to the pipeline, the performance improved significantly, boosting the F1 score to 0.92, as shown in Figure 6. It is worth noting that we evaluated extractor performance only for Unstructured High Res and Azure Document Intelligence parsers, as they provide a straightforward method for chunk-type classification.
Figure 6
This analysis demonstrates the benefits of incorporating an extractor into the RAG pipeline. Expanding on this idea, we can also implement policy or instruction extraction for chunks that are policy-heavy in our enterprise use cases. However, it is important to note that such enhancements increase the complexity and cost of the RAG ingestion pipeline.
Conclusions
Retrieval-Augmented Generation (RAG) stands out as the most suitable knowledge injection approach for enterprise knowledge-intensive use cases, offering flexibility and scalability. To maximize the effectiveness of RAG, use-case-dependent optimization is critical. From selecting the right combination of document parsers, chunkers, and embedders to incorporating advanced techniques like chunk-type-specific extractors, each component can be tailored to the unique requirements of the use case. This level of optimization can significantly enhance performance, as demonstrated by improvements in F1 scores in our experiments.
Equally important is designing a modular RAG pipeline, which allows for flexible experimentation with different components. Additionally, integrating tools like Temporal strengthens the reliability and scalability of LLM-driven, knowledge-intensive processes and services.
References
[1] What Air Canada Lost In ‘Remarkable’ Lying AI Chatbot Case https://www.forbes.com/sites/marisagarcia/2024/02/19/what-air-canada-lost-in-remarkable-lying-ai-chatbot-case/
[2] Yext Showcases Knowledge Injection Research With Large Language Models | Yext
[3] Fast Model Editing at Scale [2110.11309] Fast Model Editing at Scale
[4] Massive Editing for Large Language Models via Meta Learning https://openreview.net/forum?id=L6L1CJQ2PE
[5] WISE: Rethinking the Knowledge Memory for Lifelong Model Editing of Large Language Models [2405.14768] WISE: Rethinking the Knowledge Memory for Lifelong Model Editing of Large Language Models
[6] MELO: Enhancing Model Editing with Neuron-Indexed Dynamic LoRA https://arxiv.org/abs/2312.11795
[7] Transformer-Patcher: One Mistake Worth One Neuron Transformer-Patcher: One Mistake Worth One Neuron | OpenReview
[8] Calibrating Factual Knowledge in Pretrained Language Models [2210.03329] Calibrating Factual Knowledge in Pretrained Language Models
[9] Memory-Based Model Editing at Scale [2206.06520] Memory-Based Model Editing at Scale
[10] Augmenting Language Models with Long-Term Memory [2306.07174] Augmenting Language Models with Long-Term Memory
[11] Memory^3 2407.01178
[12] InfLLM: Training-Free Long-Context Extrapolation for LLMs with an Efficient Context Memory 2402.04617
[13] Retrieve, Summarize, Plan: Advancing Multi-hop Question Answering with an Iterative Approach 2407.13101
[14] PlanRAG: A Plan-then-Retrieval Augmented Generation for Generative Large Language Models as Decision Makers 2406.12430
[15] BlogPost: durable-rag-with-temporal-and-chainlit https://temporal.io/blog/durable-rag-with-temporal-and-chainlit
[16] Unstructured webpage https://unstructured.io/
[17] OmniAI webpage https://getomni.ai/
[18] Azure Document Intelligence https://documentintelligence.ai.azure.com
[19] Semantic chunkers https://github.com/aurelio-labs/semantic-chunkers
[20] Chonkie webpage https://docs.chonkie.ai/getting-started/installation
[21] Nomic AI webpage https://www.nomic.ai/
[22] OpenAI embedding models https://openai.com/index/new-embedding-models-and-api-updates/
[23] Jina AI webpage https://jina.ai/