The Enterprise Policy Gap
Every organization deploying large language models faces the same bottleneck: the model knows nothing about your business. It does not know your internal language, compliance policies, the regulatory changes from last quarter, your operating procedures, your product liability guidelines, customer-specific SLAs, or the institutional knowledge your teams have built over years.
This Enterprise Policy Gap represents a significant operational risk and presents reliability challenges for both large language model accuracy and agentic output consistency.
Existing enterprise customization approaches fall short:
Full fine-tuning is prohibitively expensive, requires a full retraining cycle on every policy update, and suffers from catastrophic forgetting — the model loses general reasoning while absorbing your specifics.
Parameter-efficient fine-tuning is more cost-effective but requires retraining per model update. It produces static adapters that often degrade on queries slightly different from the training data, forget previous tasks, and do not scale cleanly as policy corpora grow.
Retrieval-Augmented Generation prepends documents to the prompt, but inference costs scale quadratically with context length. Performance often degrades when reasoning over many retrieved facts simultaneously, frequently leading to the "lost in the middle" phenomenon.
To bridge the gap, Nace AI builds Metamodel that Continually Updates Language and Reasoning Model in a dynamic enterprise environment. Our approach that adapts model behavior at inference time without retraining, without large context windows, and without directly touching the primary model's weights.
What Is a Metamodel?
A Metamodel — is a small, secondary neural network whose purpose is to generate parameter adaptations for another (primary) model. Instead of storing knowledge directly in its own weights, the Metamodel produces precise, temporary modifications to the primary model conditioned on whatever knowledge enterprises want to inject.
The process works in three steps:
Company’s knowledge artifacts (policies, operating procedures, documents) are fed as input to the metamodel.
The metamodel encodes these artifacts and generates lightweight parameter adaptations for the primary model.
The primary model, reconfigured by these adaptations, produces outputs aligned with the injected knowledge.
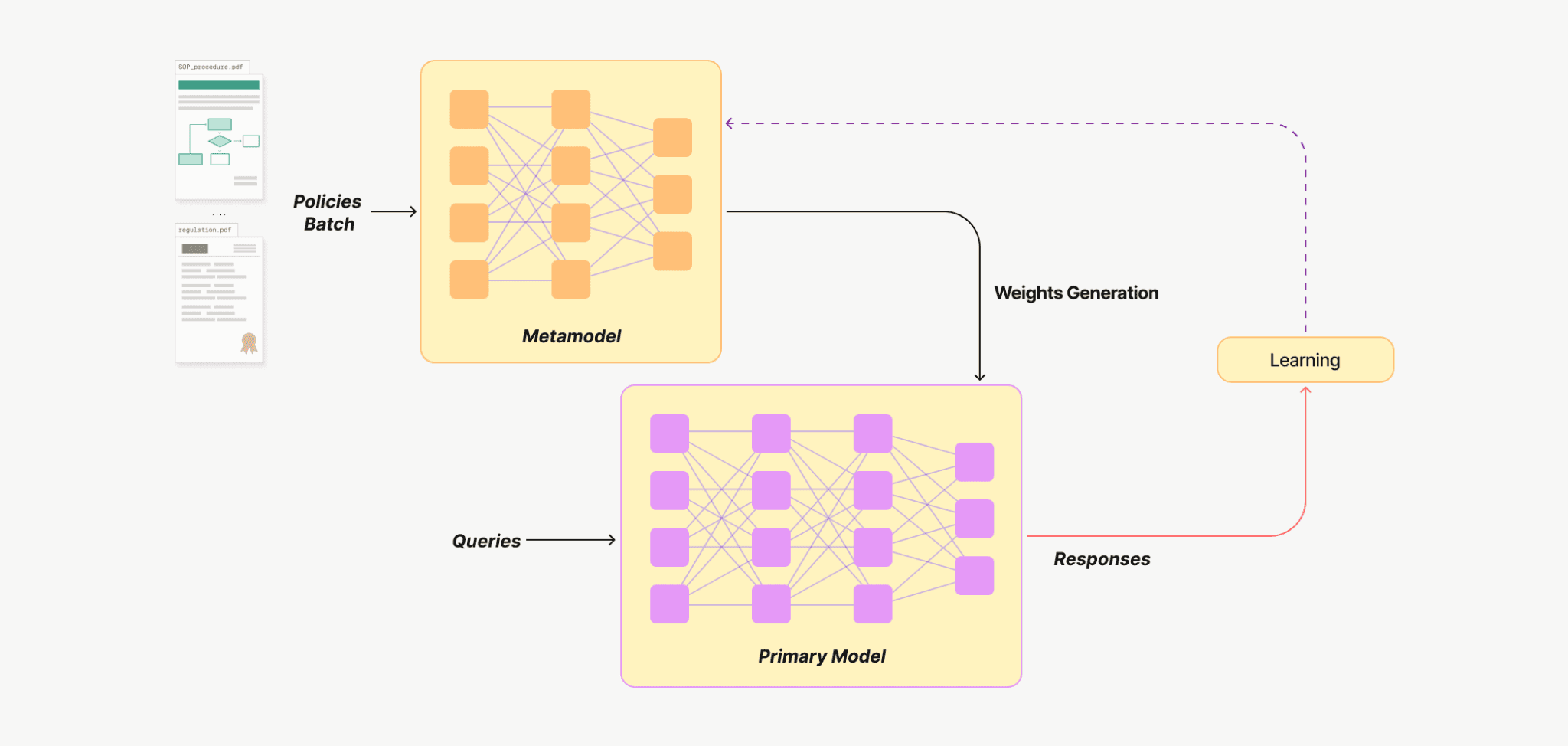
Figure 1 — Metamodel training architechture
Unlike static fine-tuning or context-heavy RAG, the Metamodel functions as a customizer that transforms enterprise policy corpora into agentic model weights. By embedding policy data into dynamic adapters injected into the primary model at test-time, it ensures high output consistency and significant cost optimization while boosting accuracy across specialized downstream tasks.
Research Results
Our empirical investigations evaluate the robustness and efficacy of Metamodels within complex enterprise environments, characterized by stochastic policy noise, non-deterministic query patterns, and temporal knowledge shifts. The subsequent analysis elucidates the mechanisms through which Metamodels achieve generalization, scalability, and adaptive fidelity under these high-entropy conditions.
Metamodel to generalize beyond its initial training scope.
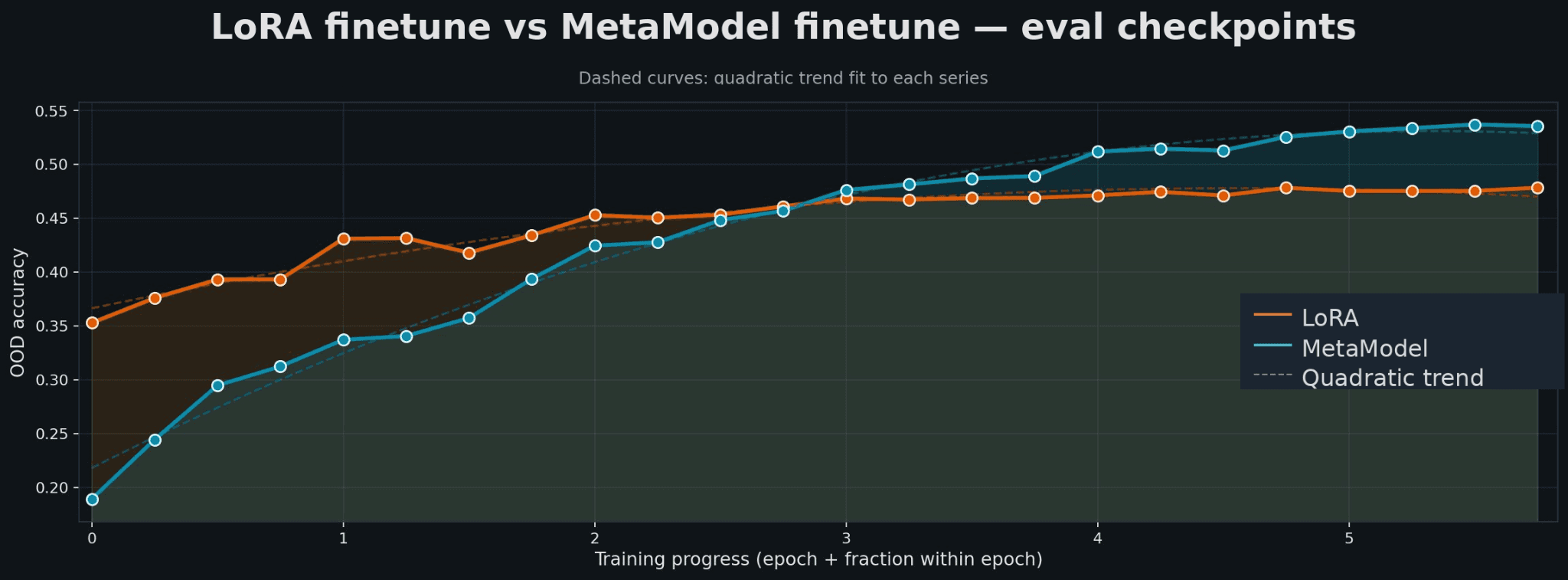
Figure 2 — Parameter Efficient Fine-Tuning vs. Metamodel comparison across training epochs
The natural comparison for our approach is LoRA fine-tuning: train low-rank adapters on your knowledge corpus, attach them at inference. It is cheaper than full fine-tuning and avoids some catastrophic forgetting.
In-distribution vs. out-of-distribution accuracy across fine-tuning methods.
Method | In-Dist Accuracy | OOD Accuracy | In-Dist vs LoRA | OOD vs LoRA |
Full Fine-Tuning | 52.2% | 39.1% | +4.7% | -3.2% |
LoRA Fine-Tuning | 47.5% | 42.3% | baseline | baseline |
MetaModel (Ours) | 47.8% | 46.1% | +0.3% | +3.8% |
Comparable in-distribution performance. Both methods converge to similar validation accuracies. If deployment queries consistently resemble training data, LoRA is a reasonable choice.
Better out-of-distribution generalization. Once sufficiently trained, the MetaModel consistently outperforms LoRA finetuning on Out-Of-Distribution (OOD) accuracy, with the gap reaching approximately 4% and continuing to grow. (Reference: Figure 2)
LoRA optimizes a static adapter for a fixed training distribution. When users ask questions that paraphrase policy in unexpected ways or combine multiple policy requirements in novel configurations, LoRA fails. To conclude, on our knowledge corpus, The MetaModel generates better LoRA adapters than directly fine tuning LoRA, under the assumption that both LoRA are trained with similar settings & configurations.
Enterprise users will not always ask questions that will match company’s internal data, it can be completely orthogonal. The metamodel is built to handle this reality. |
Metamodel Scales with Enterprise Task Complexity
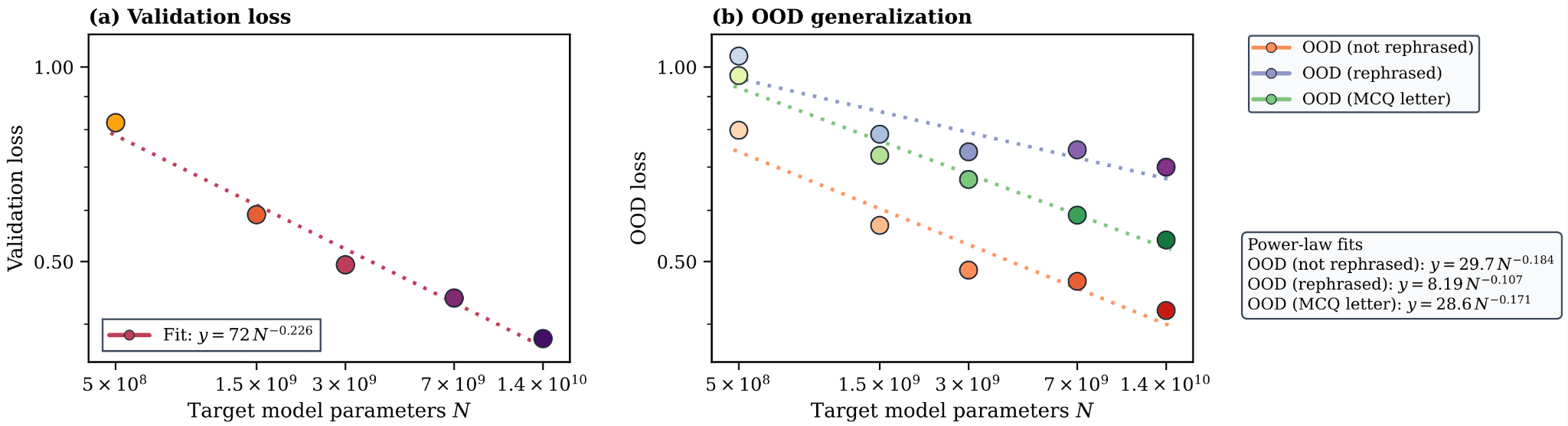
Figure 3 — Scaling behavior across primary model sizes (0.5B – 14B parameters)
To understand how Metamodel performance scales, we developed in-house dataset FactEditingWiki, a large-scale benchmark derived from Wikidata containing tens of millions of question-answer examples across 25 knowledge domains. This allowed us to run the first systematic scaling law study for Metamodel based knowledge injection.
We varied four axes independently. All four follow clean power-law relationships, the above figure denotes one of the four scaling law experiments we performed in our research:
Scaling Axis | What We Varied | Validation Accuracy | OOD Accuracy |
|---|---|---|---|
Metamodel Width | 64 → 1024 dimensions | +9.6% | +10.0% |
Metamodel Depth | 1 → 16 layers | +8.8% | +9.6% |
Primary Model Size | 0.5B → 14B parameters | +22.6% | +18.4% |
Number of Facts | 2 → 64 per query | +8.0% | +7.7% |
Primary model size has the largest impact. The steepest scaling exponent belongs to the primary model (+22.6% on validation). When choosing between a larger primary model or a larger Metamodel, the primary model provides a substantially better return on computation.
Metamodel depth and width scale comparably. Neither is a clear bottleneck in isolation; scaling both together yields the best results.
More facts reliably help. Injecting more relevant policy statements per query improves performance consistently, following a power law up to 64 facts — with no observed degradation from additional context.
Mission
The research results presented here represent the foundational steps of Nace.AI's broader mission to architect Enterprise Super Intelligence that runs the organizations. While Metamodel 1 and 2 successfully addressed critical questions regarding scalability and out-of-distribution generalization, they are only the beginning. We are currently training Metamodel 3, a next-generation system designed to solve the complexities of continual knowledge injection within code-agent harness environments. This pragmatic evolution from static adapters to dynamic, agentic intelligence marks a significant leap toward seamless enterprise AI integration. We invite you to join us on this mission as we redefine the boundaries of what specialized models can achieve.
The Enterprise Policy Gap
Every organization deploying large language models faces the same bottleneck: the model knows nothing about your business. It does not know your internal language, compliance policies, the regulatory changes from last quarter, your operating procedures, your product liability guidelines, customer-specific SLAs, or the institutional knowledge your teams have built over years.
This Enterprise Policy Gap represents a significant operational risk and presents reliability challenges for both large language model accuracy and agentic output consistency.
Existing enterprise customization approaches fall short:
Full fine-tuning is prohibitively expensive, requires a full retraining cycle on every policy update, and suffers from catastrophic forgetting — the model loses general reasoning while absorbing your specifics.
Parameter-efficient fine-tuning is more cost-effective but requires retraining per model update. It produces static adapters that often degrade on queries slightly different from the training data, forget previous tasks, and do not scale cleanly as policy corpora grow.
Retrieval-Augmented Generation prepends documents to the prompt, but inference costs scale quadratically with context length. Performance often degrades when reasoning over many retrieved facts simultaneously, frequently leading to the "lost in the middle" phenomenon.
To bridge the gap, Nace AI builds Metamodel that Continually Updates Language and Reasoning Model in a dynamic enterprise environment. Our approach that adapts model behavior at inference time without retraining, without large context windows, and without directly touching the primary model's weights.
What Is a Metamodel?
A Metamodel — is a small, secondary neural network whose purpose is to generate parameter adaptations for another (primary) model. Instead of storing knowledge directly in its own weights, the Metamodel produces precise, temporary modifications to the primary model conditioned on whatever knowledge enterprises want to inject.
The process works in three steps:
Company’s knowledge artifacts (policies, operating procedures, documents) are fed as input to the metamodel.
The metamodel encodes these artifacts and generates lightweight parameter adaptations for the primary model.
The primary model, reconfigured by these adaptations, produces outputs aligned with the injected knowledge.
Figure 1 — Metamodel training architechture
Unlike static fine-tuning or context-heavy RAG, the Metamodel functions as a customizer that transforms enterprise policy corpora into agentic model weights. By embedding policy data into dynamic adapters injected into the primary model at test-time, it ensures high output consistency and significant cost optimization while boosting accuracy across specialized downstream tasks.
Research Results
Our empirical investigations evaluate the robustness and efficacy of Metamodels within complex enterprise environments, characterized by stochastic policy noise, non-deterministic query patterns, and temporal knowledge shifts. The subsequent analysis elucidates the mechanisms through which Metamodels achieve generalization, scalability, and adaptive fidelity under these high-entropy conditions.
Metamodel to generalize beyond its initial training scope.
Figure 2 — Parameter Efficient Fine-Tuning vs. Metamodel comparison across training epochs
The natural comparison for our approach is LoRA fine-tuning: train low-rank adapters on your knowledge corpus, attach them at inference. It is cheaper than full fine-tuning and avoids some catastrophic forgetting.
In-distribution vs. out-of-distribution accuracy across fine-tuning methods.
Method | In-Dist Accuracy | OOD Accuracy | In-Dist vs LoRA | OOD vs LoRA |
Full Fine-Tuning | 52.2% | 39.1% | +4.7% | -3.2% |
LoRA Fine-Tuning | 47.5% | 42.3% | baseline | baseline |
MetaModel (Ours) | 47.8% | 46.1% | +0.3% | +3.8% |
Comparable in-distribution performance. Both methods converge to similar validation accuracies. If deployment queries consistently resemble training data, LoRA is a reasonable choice.
Better out-of-distribution generalization. Once sufficiently trained, the MetaModel consistently outperforms LoRA finetuning on Out-Of-Distribution (OOD) accuracy, with the gap reaching approximately 4% and continuing to grow. (Reference: Figure 2)
LoRA optimizes a static adapter for a fixed training distribution. When users ask questions that paraphrase policy in unexpected ways or combine multiple policy requirements in novel configurations, LoRA fails. To conclude, on our knowledge corpus, The MetaModel generates better LoRA adapters than directly fine tuning LoRA, under the assumption that both LoRA are trained with similar settings & configurations.
Enterprise users will not always ask questions that will match company’s internal data, it can be completely orthogonal. The metamodel is built to handle this reality. |
Metamodel Scales with Enterprise Task Complexity
Figure 3 — Scaling behavior across primary model sizes (0.5B – 14B parameters)
To understand how Metamodel performance scales, we developed in-house dataset FactEditingWiki, a large-scale benchmark derived from Wikidata containing tens of millions of question-answer examples across 25 knowledge domains. This allowed us to run the first systematic scaling law study for Metamodel based knowledge injection.
We varied four axes independently. All four follow clean power-law relationships, the above figure denotes one of the four scaling law experiments we performed in our research:
Scaling Axis | What We Varied | Validation Accuracy | OOD Accuracy |
|---|---|---|---|
Metamodel Width | 64 → 1024 dimensions | +9.6% | +10.0% |
Metamodel Depth | 1 → 16 layers | +8.8% | +9.6% |
Primary Model Size | 0.5B → 14B parameters | +22.6% | +18.4% |
Number of Facts | 2 → 64 per query | +8.0% | +7.7% |
Primary model size has the largest impact. The steepest scaling exponent belongs to the primary model (+22.6% on validation). When choosing between a larger primary model or a larger Metamodel, the primary model provides a substantially better return on computation.
Metamodel depth and width scale comparably. Neither is a clear bottleneck in isolation; scaling both together yields the best results.
More facts reliably help. Injecting more relevant policy statements per query improves performance consistently, following a power law up to 64 facts — with no observed degradation from additional context.
Mission
The research results presented here represent the foundational steps of Nace.AI's broader mission to architect Enterprise Super Intelligence that runs the organizations. While Metamodel 1 and 2 successfully addressed critical questions regarding scalability and out-of-distribution generalization, they are only the beginning. We are currently training Metamodel 3, a next-generation system designed to solve the complexities of continual knowledge injection within code-agent harness environments. This pragmatic evolution from static adapters to dynamic, agentic intelligence marks a significant leap toward seamless enterprise AI integration. We invite you to join us on this mission as we redefine the boundaries of what specialized models can achieve.